
|
261| 0
|
搜索引擎算法体系简介——排序和意图篇 |


 发表于 2022-9-21 16:37:12
发表于 2022-9-21 16:37:12




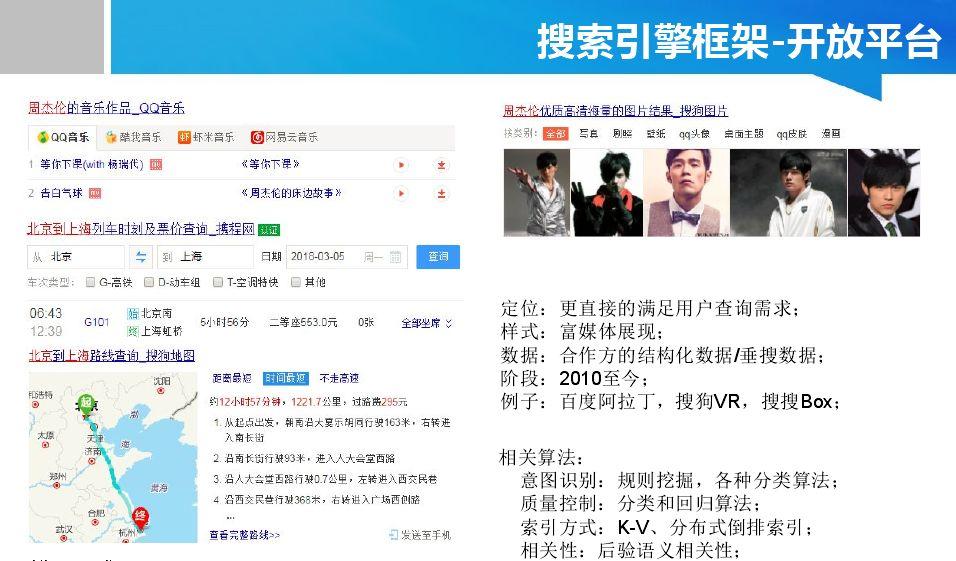

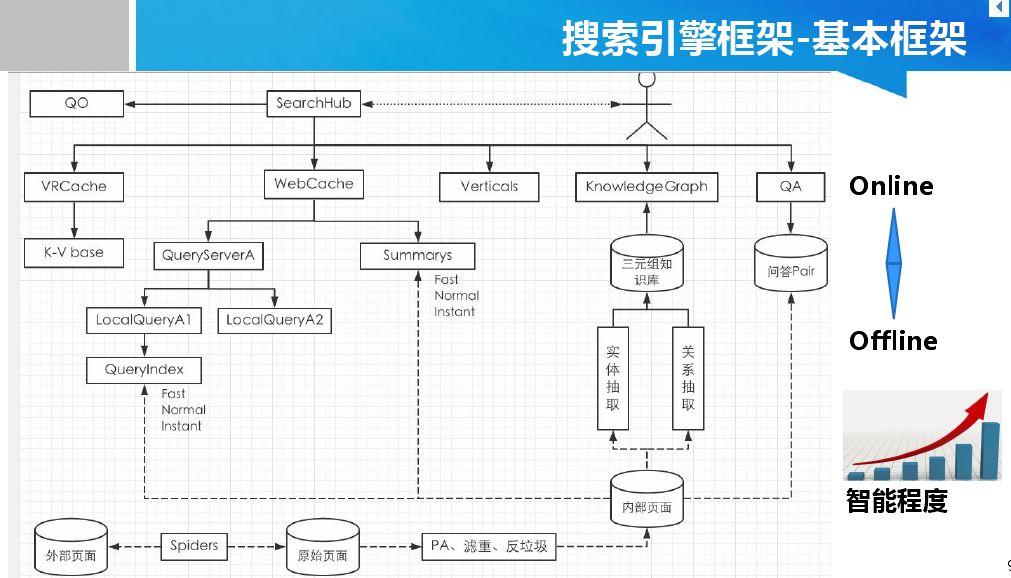

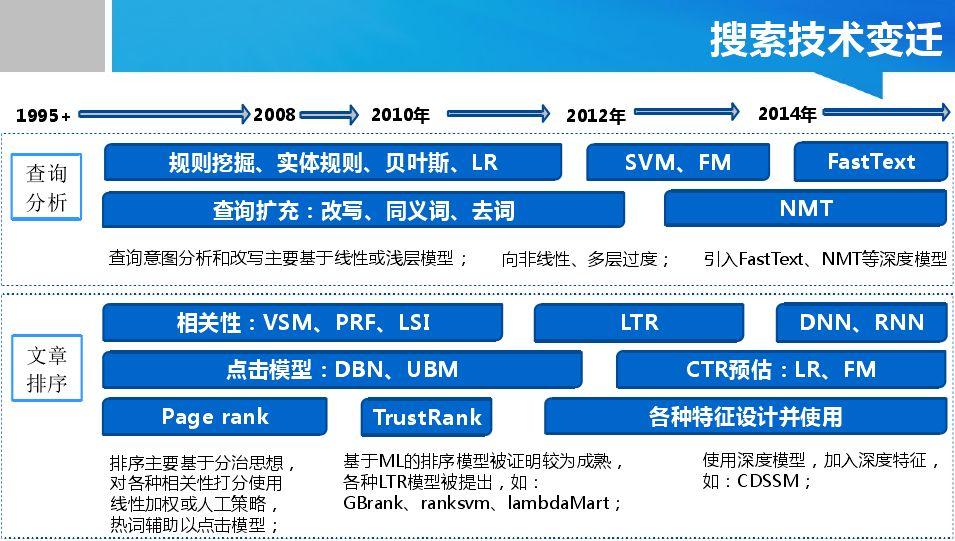

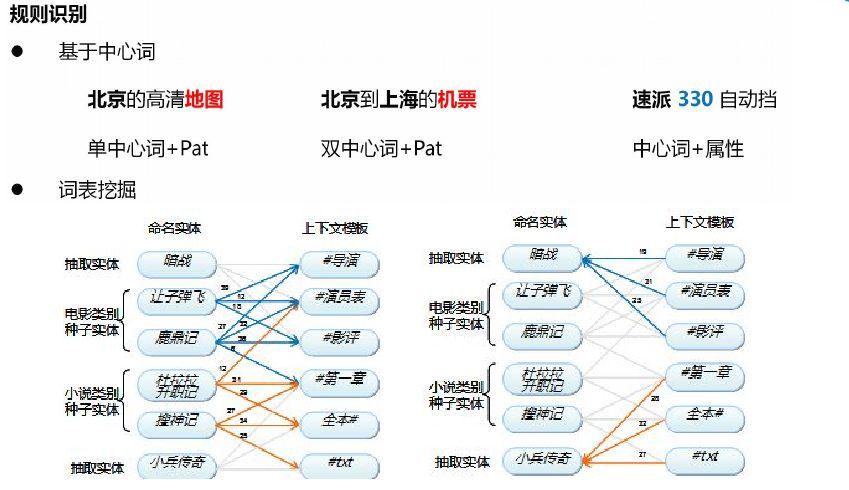


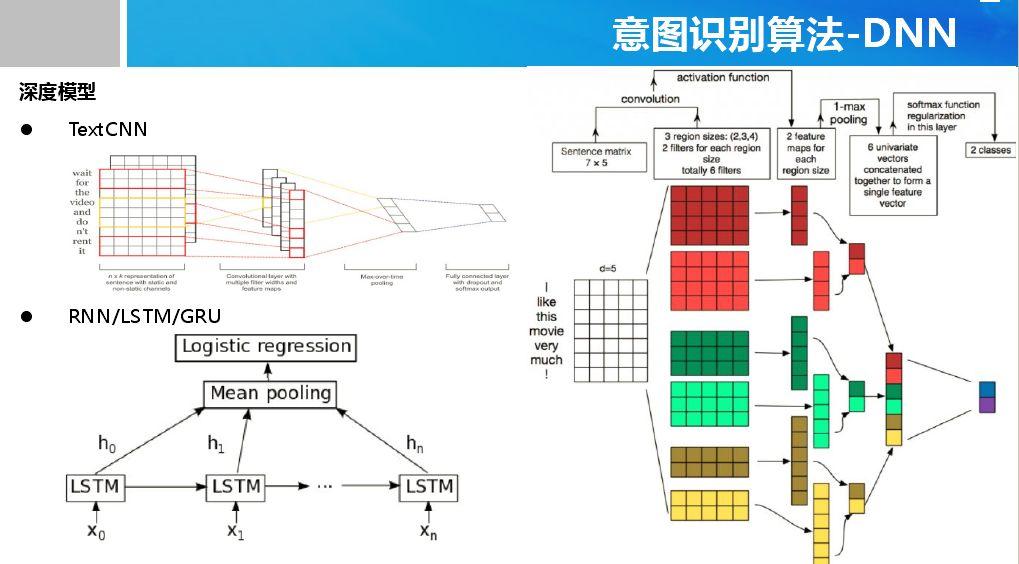
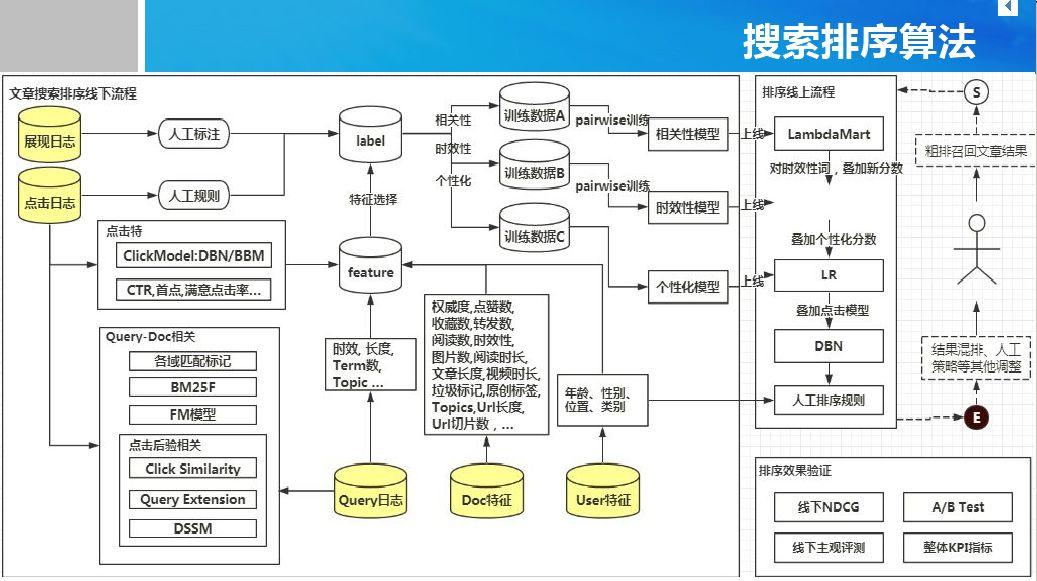

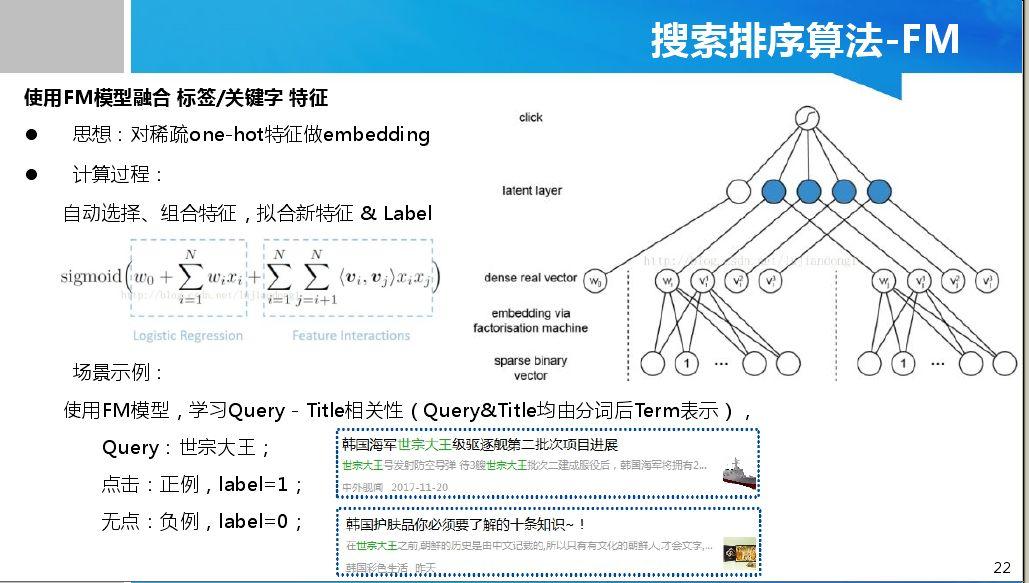

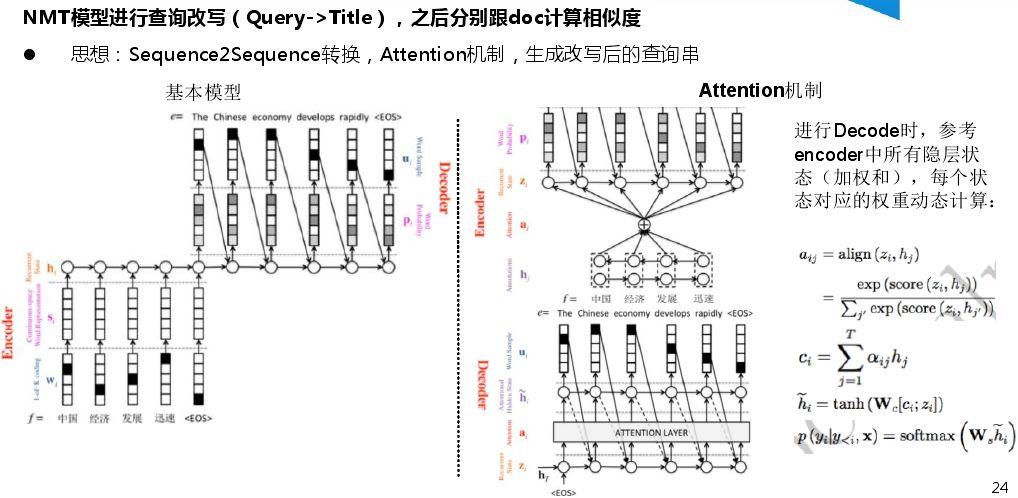
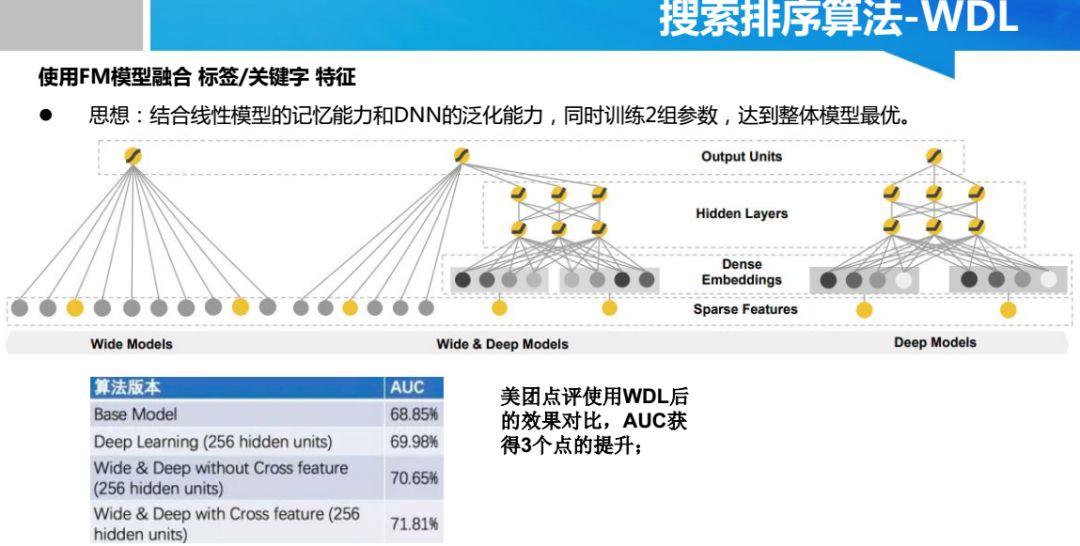
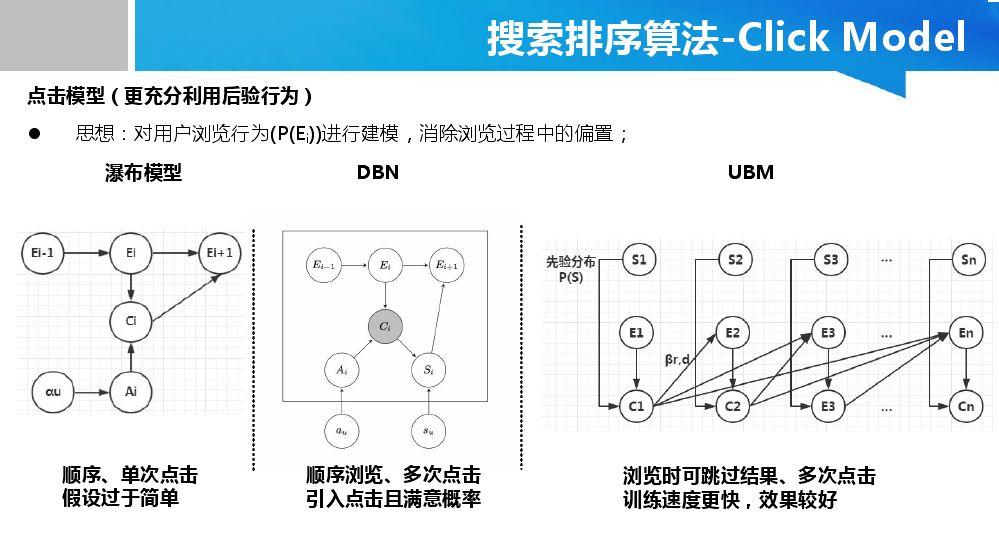



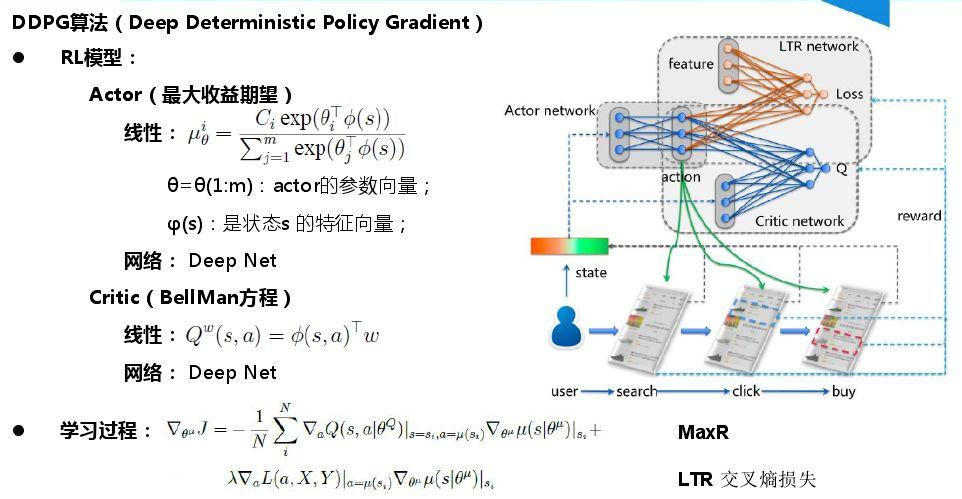

Copyright © 2001-2013 Comsenz Inc.Template by Comsenz Inc.All Rights Reserved.
Powered by Discuz!X3.4
|
261| 0
|
搜索引擎算法体系简介——排序和意图篇 |
Copyright © 2001-2013 Comsenz Inc.Template by Comsenz Inc.All Rights Reserved.
Powered by Discuz!X3.4